Mistral Small 4 : un seul modèle pour tout faire en 2026
Mistral lance Small 4, un modèle open-source de 119B paramètres qui unifie raisonnement, code et multimodal. Apache 2.0, 256K de contexte.
Mistral Small 4 : la startup francaise sort un modele d'IA qui rivalise avec les geants americains
Mistral, la startup francaise d'intelligence artificielle, vient de sortir Small 4. C'est un programme d'IA capable de discuter, de reflechir et d'ecrire du code informatique, le tout dans un seul outil au lieu de trois separement. Et il est entierement gratuit a telecharger et a modifier.
Un seul modele qui fait tout
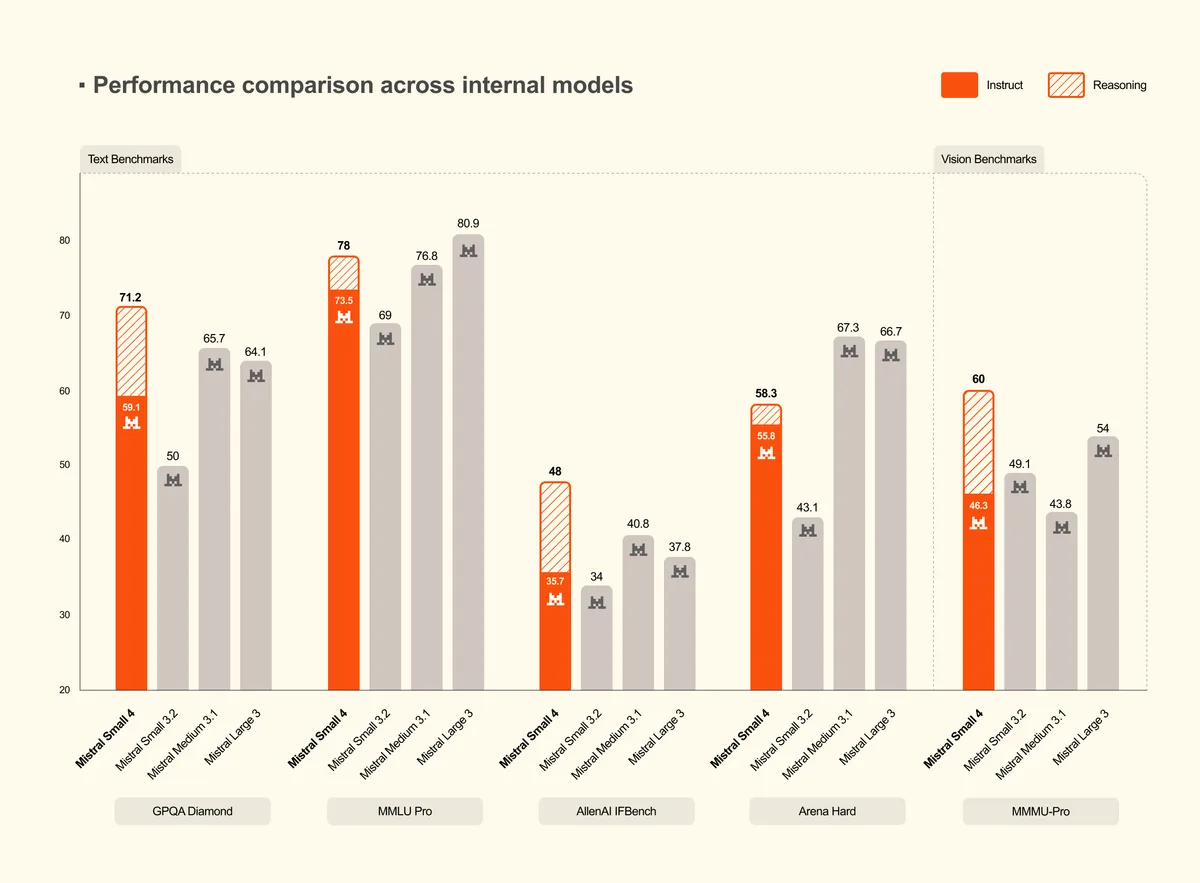
Jusqu'ici, Mistral proposait plusieurs programmes specialises. Un pour repondre vite aux questions simples, un autre pour les problemes complexes qui demandent de la reflexion, et un troisieme pour ecrire du code. C'etait comme avoir trois employes differents selon le travail a faire.
Small 4 fusionne les trois. Grace a un reglage simple, on peut lui demander de repondre vite et court, ou de prendre son temps pour decomposer un probleme etape par etape. C'est comme avoir un employe polyvalent qui sait quand il faut aller vite et quand il faut etre minutieux.
Comment ca marche, en simple
Le modele utilise une technique appelee Mixture of Experts. Imaginez un grand bureau avec 128 specialistes. Quand une question arrive, au lieu de mobiliser tout le monde, le systeme choisit les 4 specialistes les plus pertinents pour y repondre. Le resultat est aussi bon que si les 128 avaient travaille, mais ca coute beaucoup moins cher en puissance de calcul.
En chiffres, le modele a 119 milliards de parametres au total, c'est-a-dire 119 milliards de reglages qui definissent son comportement, mais seulement 6 milliards sont actifs a chaque instant. C'est comme avoir une bibliotheque geante mais ne lire que les quatre livres les plus utiles pour chaque question.
256 000 mots en une seule conversation
Small 4 peut traiter 256 000 tokens d'un coup. Un token, c'est environ un morceau de mot. En pratique, ca represente environ 500 pages de texte. On peut lui donner un roman entier, un projet informatique complet ou des centaines de pages de documentation, et il garde tout en tete pour repondre a vos questions.
Il sait aussi analyser des images : documents, captures d'ecran, schemas techniques. Pas besoin d'un outil separe.
Gratuit et open-source
Le point le plus important : Small 4 est sous licence Apache 2.0. En langage courant, ca veut dire que n'importe qui peut le telecharger, le modifier, l'adapter a ses besoins et l'utiliser en production sans demander la permission ni payer de licence. C'est comme une recette de cuisine publique que tout le monde peut reprendre et ameliorer.
C'est rare dans le monde de l'IA ou les gros modeles sont souvent proprietes privees de Google, OpenAI ou Meta.
Le probleme du materiel
Petit bemol : pour faire tourner Small 4 sur ses propres serveurs, il faut du materiel costaud. Les cartes graphiques necessaires coutent plusieurs dizaines de milliers d'euros. Pour les petites structures, Mistral propose une alternative : utiliser le modele via internet, en payant au volume d'utilisation. Vous testez via le service en ligne, vous validez que ca repond a votre besoin, et vous decidez ensuite si l'achat de materiel vaut le coup pour votre volume.
Pourquoi c'est important
Mistral est la seule entreprise europeenne a jouer dans la cour des grands de l'IA. Avec Small 4, elle prouve qu'on peut faire un modele gratuit et ouvert qui rivalise avec les modeles payants des geants americains, tout en etant plus econome en ressources. Pour les developpeurs europeens qui veulent garder le controle sur leurs outils, c'est une option serieuse.
À lire aussi
Mamba-3 : l'architecture qui veut detroner les Transformers
Together AI et Carnegie Mellon presentent Mamba-3, un modele d'IA qui promet des performances equivalentes aux Transformers pour un cout bien moindre.
Mamba-3 : SSM optimise inference, benchmarks et architecture
Analyse technique de Mamba-3, le State Space Model de Together AI qui repense l'inference LLM avec recurrence complexe, mode MIMO et noyaux Triton/TileLang.
OpenCode : l'agent de code IA open source qui explose
Avec 120 000 etoiles GitHub et 5 millions d'utilisateurs mensuels, OpenCode s'impose comme l'alternative gratuite aux agents de coding IA proprietaires.