
Sécurité des agents IA : 7 risques réels à connaître
Fuite de clés API, prompt injection, boucles infinies, suppression de fichiers... Les 7 risques concrets des agents IA autonomes et comment s'en protéger.
Un agent IA sur votre machine, c'est puissant. Et risqué.
La sécurité des agents IA autonomes est devenue un sujet incontournable en 2026. Que vous utilisiez Claude Code, Devin, AutoGPT, un workflow n8n ou tout autre système agentique, le constat est le même. Ces outils lisent vos fichiers, exécutent des commandes, envoient des messages, gèrent vos workflows. Et cette autonomie a un prix. Plus un agent peut agir seul, plus les dégâts potentiels sont importants.
Au fil de mes mois d'utilisation quotidienne d'agents IA — notamment via OpenClaw —, j'ai identifié 7 risques très concrets. Des trucs que vous devriez connaître avant de lâcher un agent dans la nature.
L'action qui part en vrille
Votre agent a accès à write, edit, exec ? Félicitations, il peut aussi supprimer vos fichiers, écraser une config critique ou lancer un rm -rf si le modèle hallucine au mauvais moment. Ce risque existe partout, de Claude Code à Devin en passant par les agents custom LangChain.
La solution, c'est d'accorder les droits au compte-gouttes. Des permissions granulaires (allow/deny par outil), un mode approbation obligatoire pour les actions destructives, et un sandboxing Docker quand c'est possible. Jamais en bloc.
La fuite silencieuse de vos secrets
Clés API, tokens, mots de passe... Tout ce qui traîne dans votre environnement peut finir dans le prompt envoyé au cloud. Une fois que c'est parti, c'est parti.
Verrouillez votre fichier .env (chmod 600), ne mettez jamais de variables d'environnement en dur dans le code, et privilégiez un agent local pour les opérations sensibles. Vérifiez aussi quelles données votre agent envoie au fournisseur de LLM. Les politiques de rétention varient d'un service à l'autre.
Le prompt injection
Votre agent lit un email ou scrape une page web. Sauf que dans le contenu, quelqu'un a planqué des instructions malveillantes. Le modèle les exécute parce qu'il ne fait pas la différence entre vos consignes et du texte piégé.
Ça touche tous les agents qui consomment du contenu externe. Bots email, agents de recherche web, workflows automatisés, chatbots connectés à des bases de données. C'est d'ailleurs l'un des points critiques dans l'architecture skills/tools/MCP qui connecte les agents au monde extérieur.
Pour limiter le risque, séparez les rôles système et utilisateur, filtrez les entrées, et appliquez le principe du moindre privilège. Un agent qui lit des emails n'a aucune raison d'avoir accès au filesystem.
La boucle infinie qui vous ruine
L'agent essaie une commande. Elle échoue. Il réessaie avec une variante. Qui échoue. Il réessaie... 200 appels API plus tard, votre facture a explosé et le problème n'est toujours pas résolu.
Mettez en place des timeouts stricts, une détection de boucle, et un monitoring en temps réel des sessions. Si un agent tourne en rond, il faut pouvoir le couper. La plupart des frameworks sérieux (Claude Code, CrewAI, AutoGPT) proposent ces mécanismes. Activez-les.
La décision techniquement correcte mais absurde
L'agent suit une logique impeccable... pour arriver à une conclusion qui n'a aucun sens. Exemple vécu : un agent qui reformatait un article entier parce qu'il avait détecté une "incohérence de style" dans un bloc de code. Oui, vraiment.
Prévoyez une validation humaine sur les actions à fort impact, un gating par mentions explicites, et des allowlists pour cadrer le périmètre d'action.
La dépendance, le risque qu'on ne voit pas venir
À force de déléguer à l'agent, on finit par ne plus savoir faire soi-même. Le jour où l'API tombe ou que l'abonnement expire, c'est la panique.
Prenez le temps de comprendre ce que l'agent fait avant d'accepter son output. L'IA est un outil, pas un remplacement de compétences. Gardez la main sur les fondamentaux.
L'hémorragie de tokens
Un prompt mal calibré, un modèle trop gros pour la tâche, des appels en boucle... et votre budget API fond en quelques heures.
Mettez du tracking de consommation, des plafonds de budget, et surtout choisissez le bon modèle pour chaque tâche. Pas besoin de GPT-4 pour classifier un email. Les modèles légers font très bien le travail quand la tâche le permet.
Les bons réflexes à adopter
La sécurité des agents IA n'exige pas de devenir expert en cybersécurité. Il suffit de suivre quelques principes de base :
- Accorder les permissions au minimum nécessaire, jamais en bloc
- Sandboxer dans un conteneur Docker ou un environnement isolé
- Activer la validation humaine pour toute action destructive ou irréversible
- Mettre en place des timeouts et des limites de budget par session
- Surveiller les logs en temps réel pour repérer les boucles ou comportements anormaux
- Séparer les données sensibles (clés API, tokens) du périmètre accessible à l'agent
- Vérifier régulièrement les politiques de rétention de votre fournisseur de LLM
Si vous ne comprenez pas ce que l'agent fait, ne le laissez pas faire. Quel que soit l'outil, les principes restent les mêmes. Le reste, c'est de la discipline.
À lire aussi
OpenClaw : une IA privée, meilleure alternative à ChatGPT
ChatGPT stocke vos conversations sur des serveurs US. OpenClaw garde tout chez vous. Voici comment avoir une IA personnelle sur WhatsApp, 100 % privée.
Agents IA vs Assistants IA : la vraie différence en 2026
Siri et Alexa obéissent. Les agents IA agissent seuls. Découvrez pourquoi cette distinction va transformer votre façon de travailler en 2026.
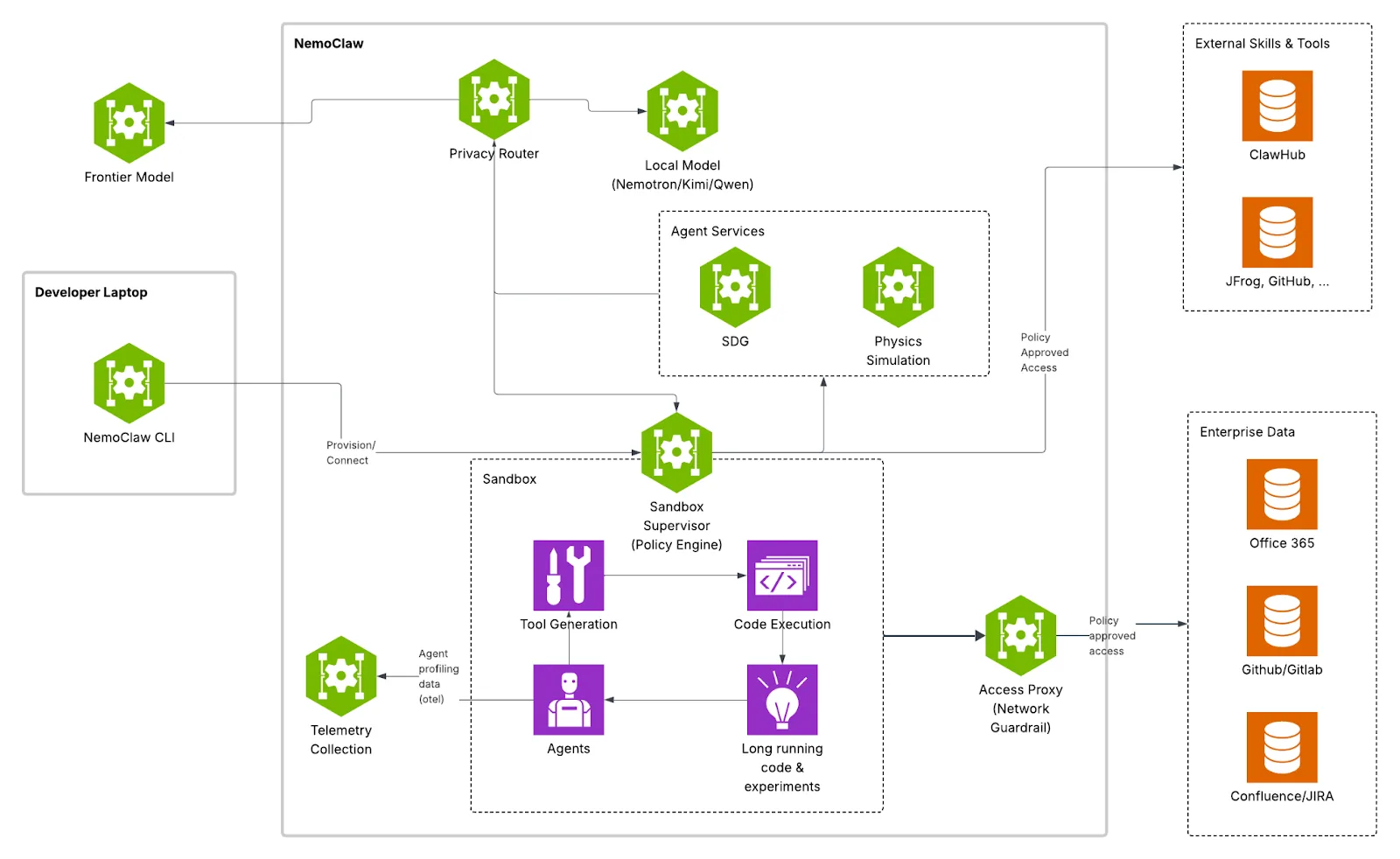
NVIDIA NemoClaw sécurise vos agents IA open-source
NVIDIA dévoile NemoClaw à la GTC 2026 : un stack open-source qui blinde OpenClaw avec isolation, chiffrement et modèles Nemotron en local.
Questions fréquentes
Les agents IA sont-ils dangereux ?
Pas plus que tout outil puissant. Le risque vient surtout d'une mauvaise configuration des permissions et d'un manque de supervision.
Comment sécuriser un agent IA ?
Commencez restrictif, sandboxez dans un conteneur, validez les actions critiques et surveillez la consommation de tokens en temps réel.
C'est quoi le prompt injection sur un agent IA ?
C'est quand du contenu externe (email, page web) contient des instructions cachées que l'agent exécute sans le savoir. On limite le risque en séparant les rôles et en filtrant les entrées.